This demo shows how we can use Kafka Streams to combine and process incoming events from multiple sources. Once the aggregation process is complete and the consolidated data is prepared, a new, enriched event will be emitted to notify relevant consumers or systems.
To demonstrate the problem, we will build an asynchronous order system for an online shopping company. The system allows the company to accept customer orders, oversee the manufacturing process, and manage shipping, all while maintaining separate services and relying on event-driven communication via Kafka topics.
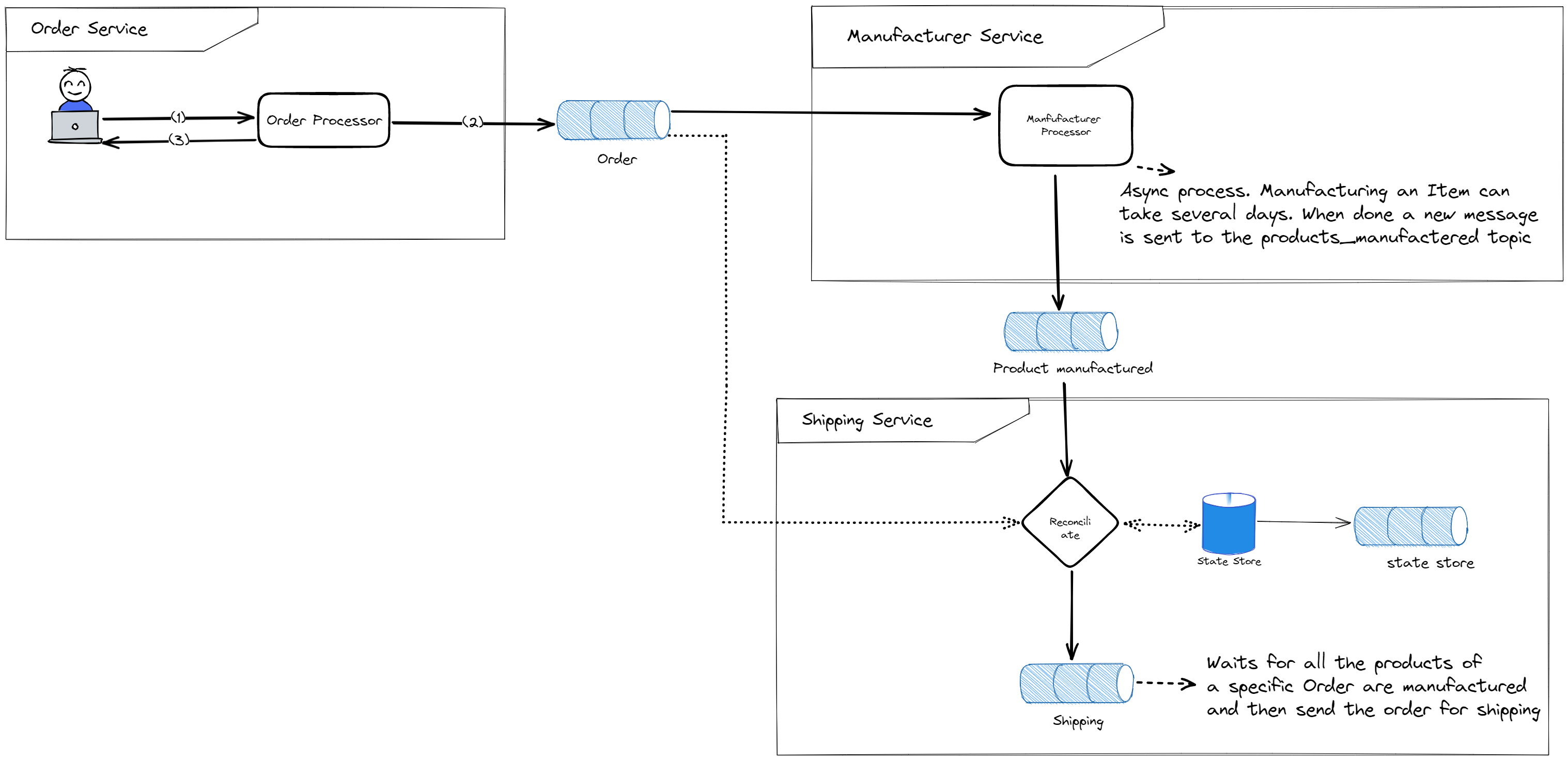
Upon examining the previous diagram, it becomes clear that the shipping service must be aware of the order status before initiating the shipping process. An order must only be shipped after all products have been manufactured. However, this system lacks a central database to keep track of each order and its status. To address this issue, we will utilize Kafka Streams to aggregate events from all the relevant topics and emit an enriched event when the order is ready to be shipped.
The stateful aggregation we will implement using Kafka Streams allows the shipping service to know the current status of an order by subscribing to and processing the events associated with both the Order and Products Manufactured topics. By doing so, we can ensure that the shipping service only ships the order once all products of the order have been successfully manufactured. This approach eliminates the need for a central database to monitor the status of each order, as the Kafka Streams application will continuously process and update the order status based on the incoming events. This aggregation will enable a more efficient and streamlined shipping process, as the shipping service will be automatically informed of the order status and can initiate the shipping process as soon as the order is ready.
The system is composed of 3 independent services:
Order service. Receives the orders from the users and stores them in a Kafka topic. In a real case, this can be a REST API.
Manufacturer service. It subscribes to messages in the order topic. When it receives a new message, it requests the manufacturer of the products.
Shipping service. After all items of the order are manufactured, the shipping service can trigger the shipping process. This service must be able to know the current order status. An order is considered ready to be shipped when all products are manufactured.
As illustrated in the diagram, our three components are entirely independent. They do not communicate directly with each other, instead, all events are transmitted through Kafka topics.
In this event-driven architecture, each service can subscribe to specific topics that contain the events relevant to their particular function. This ensures that they remain informed and up-to-date on any developments that pertain to their area of responsibility. For instance, the Manufacturing service is designed to read events from the order topics, which enables it to stay constantly updated about new orders that have been placed.
Reconciling Orders & Manufactured Products with KStreams
How can the shipping service know when an order is placed and products are manufactured to start shipping?
To tackle the challenge of determining when an order has been placed and its corresponding products have been manufactured we can use several solutions. For example, periodic polling, a basic Kafka consumer, or even a batch processing approach, all of these are valid options. However, the focus of this demo is to show the ussage of Kafka Streams.
This approach not only allows us to monitor the manufacturing process but also ensures that the shipping service is promptly informed once all the required conditions are met to start the shipping process.
Kafka Streams
Kafka Streams is an abstraction for the Kafka consumer and producer APIs that allow us to focus on the business code instead of the technical details.
Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It combines the simplicity of writing and deploying >standard Java and Scala applications on the client side with the benefits of Kafka's server-side cluster technology.
https://kafka.apache.org/documentation/streams/
The advantage of Kafka Streams lies in allowing the developer to concentrate on the business logic while the boilerplate code is handled by the Kafka Streams library. Kafka Streams allow the implementation of both stateless and stateful operations. In our case, we are attempting to implement a stateful operation, an aggregation to be precise. The aggregation we are going to implement is stateful because it requires prior knowledge of both the order products and the products manufactured information before emitting the enriched event
Stateful operations in KStreams are implemented with the help of state stores. The state stores are in-memory databases backed by RocksDB that are also persisted on a Kafka topic. Consequently, even if the application crashes, our data remains secure and the application can effortlessly resume after a restart.
Kafka Streams Processor API
The Kafka streams library does not provide any out-of-the-box aggregation for this specific case. So we will have to implement our stateful operation using the Processor API.
To avoid redefining the processor API here is the official definition:
The Processor API allows developers to define and connect custom processors and to interact with state stores. With the Processor API, you can define arbitrary stream processors that process one received record at a time, and connect these processors with their associated state stores to compose the processor topology that represents a customized processing logic.
https://docs.confluent.io/platform/current/streams/developer-guide/processor-api.html
Implementation
The shipping service consists of a KStream application that subscribes to messages from the orders and products manufactured topic, these messages are all that we need to calculate the order status. The status of the order is persisted in a State store.
This implementation results in the following topology:
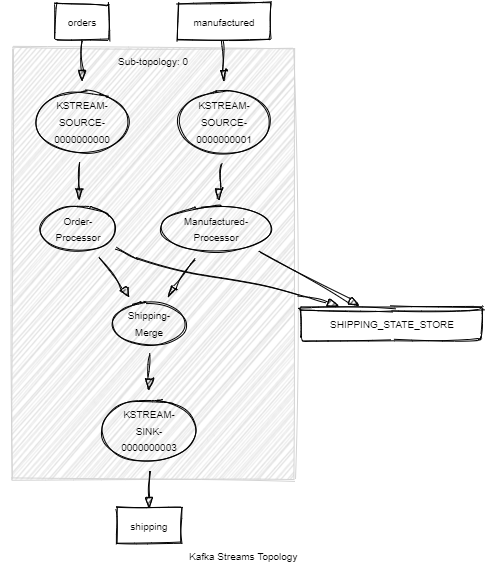
The "Order-processor" node subscribes to messages from the Order topic. For each received message it creates a new entry on the state store containing the order ID and the IDs of the products that are waiting for manufacturing.
The "Manufactured-processor" node subscribes messages from the Products manufactured topic. When it receives a message it updates the status of an existing order with the products that were manufactured. At this moment, the order status can either be "partially fulfilled" if it's still waiting for more products, or "fulfilled" if all products were manufactured. In the latter case, the KStream application will send a new message to the shipping topic so that the shipping process can be triggered, and the order dispatched to the client.
Processor Node
To implement a processor node you just have to create a class that implements the Processor interface.
The full implementation is available on GitHub, here we are going to focus only on the more relevant parts.
public void process(Record<String, T> record) {
String orderId = record.key();
OrderManufacturingStatus manufacturingStatus = stateStore.get(orderId);
if (manufacturingStatus == null) {
log.info("Order {} is not yet present in state store, creating new entry", orderId);
manufacturingStatus = new OrderManufacturingStatus(orderId);
}
updateStateStoreElement(manufacturingStatus, record);
stateStore.put(orderId, manufacturingStatus);
log.info("Order {} is present in state store, checking if all items are ready to be shipped", orderId);
boolean isOrderComplete = manufacturingStatus.isOrderComplete();
if (isOrderComplete) {
log.info("All items of order {} were manufactured, forwarding event to shipping", orderId);
Record<String, ShippingDto> shippingRecord = new Record<>(orderId, new ShippingDto(orderId), currentTimeMillis());
stateStore.delete(orderId);
context.forward(shippingRecord);
} else {
log.info("Not all items of order {} were manufactured, waiting", orderId);
}
}
It starts by extracting the orderId from the record object using the key() method.
It retrieves the current OrderManufacturingStatus from the stateStore using the orderId as the key.
If the manufacturingStatus is null, it means that the order is not yet present in the state store. In this case, it creates a new OrderManufacturingStatus object for the order. This is the case when the stream receives a message from the Orders topic.
It then calls the updateStateStoreElement method. In my implementation, I have 2 classes that extend this BaseProcessor, the ManufacturerProcessor and the OrderProcessor. Each one can enrich the current Order stored in the state store with specific information. The OrderProcessor can store the products that belong to the order, and the ManufacturerProcessor the product that was already manufactured.
The updated manufacturingStatus object is put back into the state store using the orderId as the key.
Checks if all items in the order are ready to be shipped by calling the isOrderComplete() .
If all items are ready to be shipped, it creates a new ShippingDto object for the order and forwards it to the next topic (Shipping). This finalizes the events reconciling and aggregation.
- Deletes the
manufacturingStatus entry from the state store.
If not all items of the order are ready for shipping, it just logs a message and doesn't emit a new event.
State store
As seen before, the state store plays a crucial role in this implementation. It's there where the application stores the order status that's used to decide if it should trigger the shipping process or not.
Let's see an example of the evolution of the state store for an Order with ID 1 containing 2 products, Product A and Product B. As seen in the next image, the state store evolves with the messages received from the orders and products manufactured topic. For each event received, the Kstream application updates the order status in the state store. When it detects that the order is ready to be shipped, the KStream will emit a new message to the shipping topic.

How to run the application
Clone the repository.
Use docker compose to start the Kafka cluster:
docker compose up -d
AKHQ is now accessible in the URL: http://localhost:9090/ui/docker-kafka-server/topic
Test the reconciliation process
Run the Stream application:
./gradlew runKStream
The KStream application waits for new events.
On a new terminal create a new order by running the OrderProducer main method
./gradlew runOrderProducer
You should see on the logs a message similar to the following:
Successfully sent new order to the orders topic: OrderDto[id='a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd', orderDate=2023-05-08T21:37:38.571850862, items=[ProductDto[id=1, name='Iphone'], ProductDto[id=2, name='Samsung']]]
After running OrderProducer, an order with ID a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd is created, containing 2 items. The app waits for both items to be manufactured before sending the enriched event to the shipping topic.
Check the logs of the Stream application
With the order already present in the Kafka "orders" topic, you should see the following logs in the Stream application:
INFO c.h.s.OrderManufacturingStatus - 0/2 manufactured products
INFO c.h.shipping.processor.BaseProcessor - Not all items of order a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd were manufactured, waiting
You can see on the previous log lines that the stream application detected a new order. This order contains 2 products that weren't yet manufactured. So the stream application is waiting for the products to be manufactured before emitting a new message to the shipping topic.
Produce a message to the "products manufactured" topic containing the first item of the order.
./gradlew runProductManufacturedProducer --args='a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd 1'
Replace the args parameter with the order Id generated in step 2.
Check the KStream application logs, you should see the information that 1 out 2 products were manufactured. However, the KStream application is still waiting for the second one before shipping the order.
INFO c.h.s.OrderManufacturingStatus - 1/2 manufactured products
INFO c.h.shipping.processor.BaseProcessor - Not all items of order a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd were manufactured, waiting
Produce a message to the "products manufactured" topic containing the last item of the order.
./gradlew runProductManufacturedProducer --args='a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd 2'
Replace the args parameter with the order Id generated in step 2.
With the last item of the order manufactured the KStream application can now send the order for shipping. If we check the logs we see that was what happened. The KStream reconciled all the information and detected that all items of the order were manufactured. So it sent a new message to the shipping topic.
INFO c.h.s.OrderManufacturingStatus - 2/2 manufactured products
INFO c.h.shipping.processor.BaseProcessor - All items of order a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd were manufactured, forwarding event to shipping
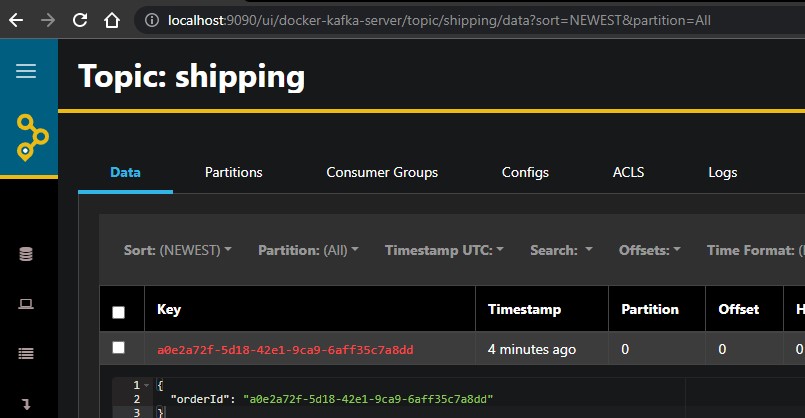
Check the shipping topic content
Open AKHQ and navigate to the shipping topic. You should see a new message there.
Check the content of the shipping-reconciliation-app-SHIPPING_STATE_STORE-changelog topic
As we saw before, the content of the state store is backed by a Kafka topic. You can verify how the state store changed over time by checking the shipping-reconciliation-app-SHIPPING_STATE_STORE-changelog topic.
--- New Order created in the state store
a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd | Value: {
"orderedProducts" : [ {
"id" : 1,
"name" : "Iphone"
}, {
"id" : 2,
"name" : "Samsung"
} ],
"manufacturedProducts" : [ ]
}
--- Order Updated with Product 1 manufactured
a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd | Value: {
"orderedProducts" : [ {
"id" : 1,
"name" : "Iphone"
}, {
"id" : 2,
"name" : "Samsung"
} ],
"manufacturedProducts" : [ {
"orderId" : "a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd",
"productId" : 2,
"manufacturedDate" : "2023-05-21T22:17:51.4358431"
} ]
}
--- Order Updated with Product 2 manufactured
a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd | Value: {
"orderedProducts" : [ {
"id" : 1,
"name" : "Iphone"
}, {
"id" : 2,
"name" : "Samsung"
} ],
"manufacturedProducts" : [ {
"orderId" : "a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd",
"productId" : 1,
"manufacturedDate" : "2023-05-21T22:17:56.5795659"
}, {
"orderId" : "a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd",
"productId" : 2,
"manufacturedDate" : "2023-05-21T22:17:51.4358431"
} ]
}
--- tombstone to delete the record
a0e2a72f-5d18-42e1-9ca9-6aff35c7a8dd | Value: null
To explore the various ways the KStream application responds to different scenarios, you can experiment by executing the commands in alternate sequences. For instance, you might consider sending a message to the "products manufactured" topic before dispatching the order to the "orders" topic. By doing so, you will observe that the KStream application is capable of effectively managing this particular situation. This successful handling can be attributed to the fact that the KStream application was specifically designed to accommodate the asynchronous nature of Kafka, which inherently allows for messages to be received in any given order.
Unit Testing
Even though it's just a demo, I wanna show you how we can unit test this KStream app.
To create the unit tests we use the kafka-streams-test-utils. Kafka Streams Test Utils is a testing library provided by Apache Kafka for testing Kafka Streams applications. It offers a set of utilities and helper classes that simplify the process of writing unit tests for Kafka Streams-based applications.
When writing tests for Kafka Streams applications, it is important to simulate the Kafka topics and streams to validate the correctness of the application's logic. Kafka Streams Test Utils provides the necessary abstractions and methods to achieve this.
import com.hugomalves.common.JSONSerde;
import com.hugomalves.manufacturer.ProductManufacturedDto;
import com.hugomalves.order.OrderDto;
import com.hugomalves.order.ProductDto;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.test.TestRecord;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.time.LocalDateTime;
import java.util.List;
import java.util.Properties;
import java.util.Set;
import static com.hugomalves.common.Configurations.*;
import static org.hamcrest.CoreMatchers.is;
import static org.hamcrest.CoreMatchers.nullValue;
import static org.hamcrest.MatcherAssert.assertThat;
class ShippingKstreamApplicationTest {
private TopologyTestDriver testDriver;
private TestInputTopic<String, OrderDto> ordersTopic;
private TestInputTopic<String, ProductManufacturedDto> productManufacturedTopic;
private TestOutputTopic<String, ShippingDto> shippingTopic;
private final ShippingKstreamApplication shippingKstreamApplication = new ShippingKstreamApplication();
@BeforeEach
public void setup() {
Properties props = new Properties();
props.setProperty(StreamsConfig.APPLICATION_ID_CONFIG, "shipping-reconciliation-app-test");
props.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "dummy:1234");
props.setProperty(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
Topology topology = shippingKstreamApplication.buildTopology();
testDriver = new TopologyTestDriver(topology, props);
Serdes.StringSerde keySerde = new Serdes.StringSerde();
JSONSerde<OrderDto> orderSerde = new JSONSerde<>(OrderDto.class);
JSONSerde<ProductManufacturedDto> manufacturedSerde = new JSONSerde<>(ProductManufacturedDto.class);
JSONSerde<ShippingDto> shippingDtoSerde = new JSONSerde<>(ShippingDto.class);
ordersTopic = testDriver.createInputTopic(ORDERS_TOPIC, keySerde.serializer(), orderSerde);
productManufacturedTopic = testDriver.createInputTopic(MANUFACTURED_TOPIC, keySerde.serializer(),
manufacturedSerde);
shippingTopic = testDriver.createOutputTopic(SHIPPING_TOPIC, keySerde.deserializer(), shippingDtoSerde);
}
@AfterEach
public void tearDown() {
testDriver.close();
}
@Test
void order_shipped_after_manufactured() {
ProductDto product1 = new ProductDto(1L, "Product 1");
ProductDto product2 = new ProductDto(2L, "Product 2");
OrderDto orderDto = new OrderDto(Set.of(product1, product2));
String orderId = "bc35d5f1-c3c1-4d4d-9a04-89f6e76f29cd";
ordersTopic.pipeInput(orderId, orderDto);
ProductManufacturedDto product1Manufactured = new ProductManufacturedDto(orderId, 1L, LocalDateTime.now());
ProductManufacturedDto product2Manufactured = new ProductManufacturedDto(orderId, 2L, LocalDateTime.now());
productManufacturedTopic.pipeInput(orderId, product1Manufactured);
productManufacturedTopic.pipeInput(orderId, product2Manufactured);
List<TestRecord<String, ShippingDto>> outputRecords = shippingTopic.readRecordsToList();
assertThat(outputRecords.size(), is(1));
TestRecord<String, ShippingDto> shippingRecord = outputRecords.get(0);
assertThat(shippingRecord.getKey(), is(orderId));
assertThat(shippingRecord.getValue().getOrderId(), is(orderId));
Object stateStoreElement = testDriver.getKeyValueStore("SHIPPING_STATE_STORE").get(orderId);
assertThat(stateStoreElement, is(nullValue()));
}
}
Conclusion
Kafka Streams provides a powerful solution for reconciling and aggregating events in an asynchronous, event-driven architecture. By implementing stateful operations using the Processor API and state stores, we can efficiently track the status of orders and trigger the shipping process at the appropriate time. This approach eliminates the need for a central database, improves scalability, and enhances the overall efficiency of an online shopping system.
Resources
https://github.com/hugo-ma-alves/kafka-streams-reconciliation [code used for this demo]
https://kafka.apache.org/34/documentation/streams/developer-guide/
https://kafka.apache.org/21/documentation/streams/developer-guide/testing.html
https://microservices.io/patterns/data/event-sourcing.html
https://learn.microsoft.com/en-us/azure/architecture/patterns/event-sourcing



